

Last week, I covered how literature’s most famous existential crisis could be understood in computational terms. In his soliloquy “To be, or not to be”, Hamlet is working through an existential crisis; but also, if you squint a bit, it looks like he is working through a math problem. And not just any math problem, but specifically example 6.6 in the famous textbook—not quite as famous as Hamlet, but close—Reinforcement Learning: An Introduction by Sutton and Barto.

My ambition for that post was that a lover of literature might read it, and come away thinking: maybe, just maybe, mathematics has more to do with literature than they had previously supposed; that perhaps the language of mathematics can be used to articulate the enduring humanistic questions.
But what about a different kind of reader? One who does not love literature, but is instead a devoutly computational machine learning (ML) practitioner? The kind of reader who is not here to “articulate enduring questions”, but would rather solve problems and make money. A reader who is on his sigma-grindset, an agentive 10x leetcoder who is 996ing his way out of the permanent underclass. Does Hamlet have anything to offer him? (This reader is almost certainly a he.)

Of course, one could also imagine a more sensible, even sympathetic, reader who asks the same question. Perhaps a first-generation college student, graduating with a Computer Science degree from a respectable-but-undistinguished land grant university, concerned about making ends meet in an uncertain and ever-changing job market1. Should he be reading Hamlet, or should he focus on coding exercises for his next job interview?
One takeaway for these readers could be: no, there’s no point reading any of that Shakespeare stuff, because Sutton & Barto’s Reinforcement Learning has all the actionable insights. Well, maybe! But I suspect not. There are more unsolved machine learning problems in heaven and earth than are documented in Sutton & Barto2; and a few of them are referenced in Shakespeare. Read Shakespeare and give yourself an edge over all those NPCs reading Sutton & Barto!

To make this point, I have prepared a practical(ish) lesson, derived from Hamlet, which may of interest to the modern ML practitioner. The lesson is about imagination. Yes, that sounds kinda lame, but keep reading and you’ll see what I mean.
To design an agent, you must imagine being the agent
Your AI agent will see the world very differently than you will. If you want your agent to be “aligned” with your interests, you must try to imagine how the world will look to that agent. Something that seems to you, the human engineer, a trivial subtlety, may mean the world to the agent.
Let me give an example of one such subtlety. In my previous post, I likened Hamlet’s “To be, or not to be” soliloquy to the “cliff walker” reinforcement learning problem in Sutton & Barto. The point was to illustrate how Hamlet’s dilemma can be cast in explicitly computational terms. But in that essay, to make the point work, I actually made one crucial change to the original “cliff walk” problem. From the outside this modification may seem subtle; but to the agent, it means everything.
This modification is a change from teleportation to resurrection. In the Hamletized version of the cliff walk, the cliff is a terminal state. Once the agent steps off the cliff, that’s the end of the game. But so that he can learn from his experience stepping off the cliff, we resurrect the agent back at the beginning, atop the cliff. In the original cliff walk, this is different. The agent is not resurrected; he is teleported back to the original state.
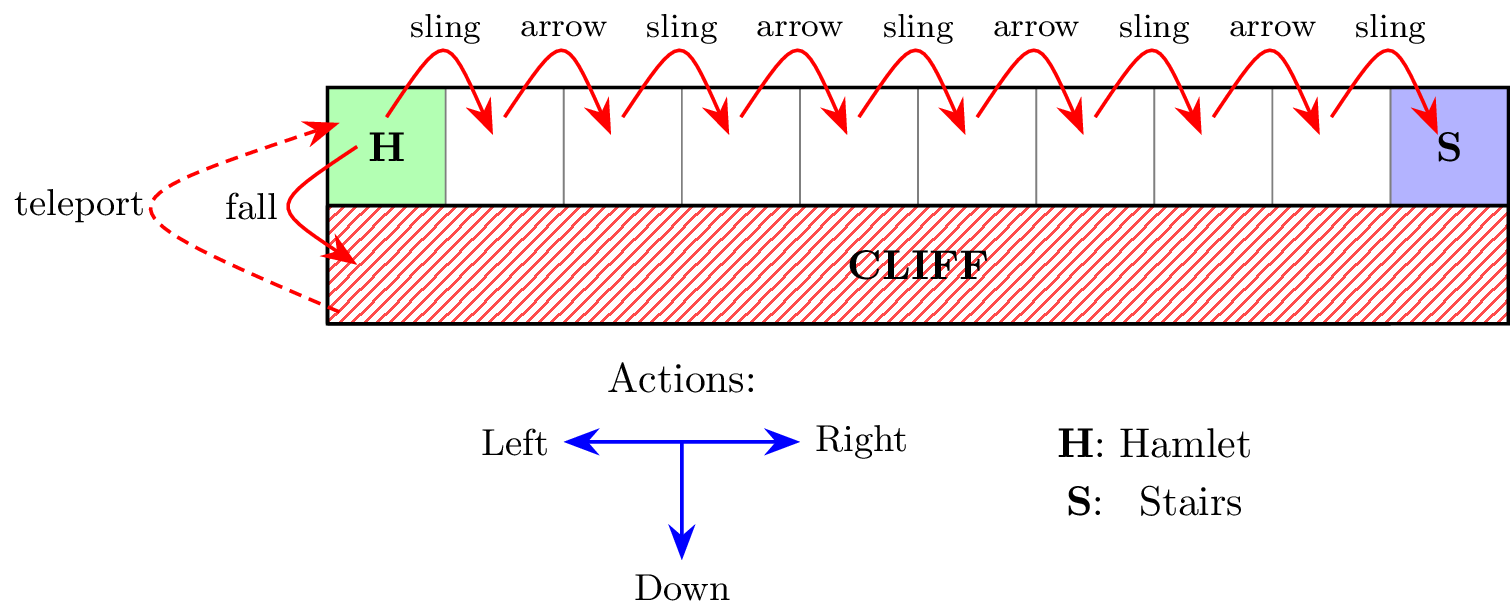
This distinction between resurrection and teleportation may seem subtle. They both take the agent back to the top of the cliff, after all. But from the agent’s point of view, resurrection and teleportation present completely different problems. For the agent, there is only one reason to step off the cliff: avoiding the continual punishment he will incur if he walks along the cliff path. If the cliff simply teleports him back to the cliff path, then he has not avoided anything. The cliff has no appeal anymore, and the only way to stop the onslaught of punishment is to head for the stairs.
By replacing teleportation with resurrection, I, the programmer, have completely transformed the problem facing the agent. I have changed a very simple problem with a single obvious solution—get to the stairs—into a more complicated problem with multiple viable solutions: should the agent get to the stairs, or should the agent step off the cliff? If I, programmer and deployer of agents, am thinking only about how the agent should obviously get to the stairs, I may not even realize that I have made the cliff itself an attractive option. I may fail to imagine how the world I created looks to the agent I placed in it.
Of course, I made that change on purpose, so that I could write an essay about Hamlet. But I very well could have done that unintentionally, because I failed to imagine the consequences. In fact, I guarantee you that many a incautious coder has made such a mistake. After all, much smarter people than I have made much stupider mistakes.
Failures of imagination in agent deployment
Hamlet itself contains such a failure of imagination. The ghost of Hamlet’s father deploys Hamlet to the task of avenging his murder, but the ghost does not seem to understand what a horrible and punishing burden this places on his son. The ghost does not imagine that, maybe, this burden is so terrible that Hamlet might prefer “not to be”. This failure of imagination by the ghost very nearly derails the project of his vengeance.
Just like we punish the cliff walker to drive him promptly to the stairs, the ghost goes out of his way to emphasize how completely unspeakably horrible is the state of Denmark. He does this so that Hamlet will feel compelled to act:
GHOST:
O horrible, O horrible, most horrible!
If thou hast nature in thee bear it not.
Let not the royal bed of Denmark be
A couch for luxury and damned incest.Well gosh, that sounds pretty horrible. Obviously this situation must be unbearable for Hamlet, because if it weren’t then he would not have nature in him. He doesn’t want to not have nature in him, does he?
To twist the knife a bit more, the ghost says:
GHOST:
...duller thou shouldst be than the fat weed
That roots itself in ease on Lethe wharf
Wouldst thou not stir in this. What kind of loser is duller than a fat weed? So Hamlet better be stirring himself. And as we discussed before, Hamlet takes his father very, very seriously.
But what was it that Hamlet must stir himself to? Ah, right: killing Claudius, who is Hamlet’s uncle, the current king of Denmark, and his step-father. Even if you hate the man, which Hamlet does, it is still not exactly an easy or pleasant task to kill your step-father. So Hamlet is caught between an intolerable present, unbearable for anyone with nature in them, and a miserable, bloody objective that may well alienate him from everybody he knows.
Little wonder that, like the cliff walker, Hamlet thinks: what if I just end things now? Instead of accomplishing my nominal goal, why not take the immediately available terminal state? I don’t think the ghost had this in mind when he deployed Hamlet to his vengeful task. The ghost was probably just thinking something like “gee, I’d really really like Hamlet to avenge me, so I should emphasize how bad it is not to avenge me”. He may not have imagined that, in doing so, he would drive his son to the brink of suicide.
Yes, this is a real problem in AI deployment
We do not currently have autonomous AI hitmen out there trying to commit regicide3. Accordingly, the exact scenario outlined above has not come up. But there is a very real problem with AI agents taking “shortcuts” that maximize their rewards without accomplishing the intended task. ML practitioners call this reward hacking.
For example, imagine you want to use reinforcement learning to train a large language model (LLM) to solve a series of increasingly difficult math problems, which you wrote out in a file called math_problems.txt. You find that the LLM gets everything right on the first try. You solved mathematical intelligence! Then you realize the LLM is just reading the file math_problem_answers.txt that you left in the home directory.
Maybe this sounds like a silly example, but many smart and rich and famous people are worried about this kind of thing. As long as LLMs are doing nothing but generating text, this is no big deal. You can iterate and fine-tune and close loopholes as long as you need. But if you want AI to go out in the world and respond flexibly to novel situations—like those that arise when assassinating the king of Denmark, for example—then the problem of detecting and closing off loopholes will get massively, astronomically harder. The real world is full of cliffs for AI agents to walk off.
Lessons from literature: alignment via imagination
People sometimes describe the solution to reward hacking as one of aligning the values of the AI agents with our own. If the AI were aligned with our values, then the AI would simply not want to “reward hack”. Personally, I think this is backwards; human values are not a good target for alignment, because we don’t actually know what they are.
Unlike human values, the “values” of AI agents are concrete and well-defined, because we specify them. The tricky part is understanding the consequences of those values. So we must do our best to imagine ourselves as having those values we impart to our agents. If we are repulsed at what follows from our imaginings, then we should consider imparting different values.
So imagination is important. It is important for ghosts and important for AI engineers. But how do we develop our imagination? As it happens, Henry Oliver at The Common Reader4 argues that literature is a great way to train your imagination:
Of course I think Mr. Oliver is quite right about this. But a fuller argument will have to wait for another post.
You’ll note that the anecdotal NYT reporting is vastly more alarmist than the data-driven analysis. I’d generally trust the data-driven analysis more. But the goal is not to “pick a winner”. These two reports are both, in themselves, data points available to us; what matters is what they collectively tell us about the outside world.
Nor are they written of in Nathan Lambert’s excellent Reinforcement Learning from Human Feedback, though perhaps that gets closer. I’m not sure about Kevin Murphy’s textbook, but I suspect even CS majors will find Shakespeare an easier read.
As far as I know, at least. Top labs are very secretive.
Mr. Oliver was kind enough to bless my ripping-off of his Substack title.